北京2023年9月21日 /美通社/ -- 随着生成式AI快速发展,人工智能在各行各业广泛应用,AI算力需求剧增,AI芯片多元化趋势凸显,带来了芯片开发成本高、多元芯片使用难等挑战。近日,浪潮信息面向全行业公布了《开放加速规范AI服务器设计指南》(以下简称《指南》)。《指南》基于浪潮信息在开放加速计算领域丰富的产品研发和工程实践经验,为AI加速卡和系统设计提供参考,大幅缩短AI加速卡与AI服务器的适配周期,促进生成式AI多元算力发展,助力用户把握生成式AI爆发带来的算力产业巨大机遇。
AI算力需求爆发,芯片多元化难题亟需破解
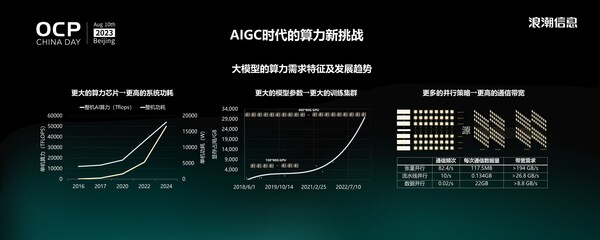
当前,生成式AI技术飞速发展,引领了新一轮AI创新浪潮。随之而来的是生成式AI算力需求猛增,推动算力产业转型升级。Henessy和Patterson在几年前的《计算机架构的新黄金时代》中就引入了特定领域体系架构(Domain Specific Architectures,DSAs)的概念,即随着通用算力技术的演进逐渐减缓,针对特定问题或领域定制计算架构变得愈发重要。基于DSAs思想设计的AI计算芯片,在特定人工智能工作负载下展现出超越通用芯片的处理能力,这极大地推动了多元化AI芯片的发展。
目前,全球已有上百家公司投入新型AI加速芯片的开发,但也带来了新的挑战。主要表现在,单机性能、功耗和扩展性更高,算力平台规模更大,对卡间互联、网络带宽和延迟提出了更高的要求。加速卡间通信的数据量越来越多,仅仅通过传统的PCIe P2P通信已经无法满足超大规模深度学习模型的要求。
为了解决这些问题,芯片公司相继推出了各自非标准PCIe CEM形态的AI加速卡,这些新形态的AI加速卡支持更高的功耗和更强大的卡间互联能力。但不同厂商采用不同技术路线,导致不同芯片需要定制化的系统硬件平台承载,系统平台研发通常大约需要6到12个月的时间。专有AI计算硬件系统开发周期长、研发成本高,严重阻碍了新型AI加速芯片的研发创新和应用推广。
OAI架构为超大规模深度神经网络模型而生
开放计算组织OCP在2019年发布了专门面向大模型训练的开放加速计算(OAI)系统架构。Mezz扣卡形态的加速器具备更高的散热和互联能力,可以承载具有更高算力的芯片。同时,它有非常强的跨节点扩展能力,可以很轻易地扩展到千卡、万卡级的平台,支撑大模型的训练。这个架构是天然适用于超大规模深度神经网络训练的计算架构。
但是,在产业落地过程中,很多厂商所开发的加速卡依然存在硬件接口不统一、互连协议不统一,同时软件生态互不兼容,带来了新型AI加速卡系统适配周期长、定制投入成本高的落地难题,导致算力供给和算力需求之间的剪刀差不断加大,行业亟需更加开放的算力平台,以及更加多元的算力支撑大模型的训练。
此外,由于各种类型AI芯片的连接接入标准不同,用户在使用多元AI芯片系统时还会遇到系统适配、芯片驱动、互联互通、功耗管理、安全传输、易用性等各类问题,使用户在部署多元AI芯片算力系统时面临巨大挑战。
从开放加速基板到千卡算力平台落地,浪潮信息的多元算力之路
芯片多元化、芯片生态割裂化是人工智能发展道路上必须要解决的挑战。基于这一洞察,浪潮信息从2018年就开始布局,持续推进开放加速规范(OAM)建立和产品技术创新,力图从系统架构层面帮助芯片厂商降低适配周期和研发成本,助力用户更快速、更方便地使用多元AI算力。
浪潮信息做的首要工作是打造一款通用加速器基板UBB,能够兼容多种OAM芯片,并在此基础上研发计算系统。2019年,浪潮信息开发出了首个开放加速计算系统MX1。MX1采用高带宽、双供电等技术,21英寸系统可支持多种符合OAM规范的AI加速器,芯片互联总带宽达到224Gbps,并提供全互联(Fully-connected)和混合立体互联HCM(Hybrid Cube Mesh)两种互联拓扑,方便用户针对不同神经网络模型,根据芯片通信的需求灵活设计芯片互联方案。
MX1推出后,市场需求表明,多元芯片大规模落地需要整机服务器的支持,因此浪潮信息又投入力量进行OAM服务器的研发。2021年,浪潮信息发布业界首款OAM服务器NF5498A5,在19英寸机箱中集成集成8颗OAM加速卡和2颗高性能CPU,卡间互连带宽448 GB/s。2022年,推出液冷OAM服务器"钱塘江",实现8颗OAM加速器和两颗高功耗的CPU的液冷散热,液冷散热覆盖率超过90%,基于"钱塘江"构建的液冷OAM智算中心解决方案,千卡平台稳定运行状态下PUE值小于1.1。今年又发布了新一代开放加速AI服务器NF5698G7,支持8颗OAM高速互联的Gaudi2加速器,基于全PCIe Gen5链路,H2D互联能力提升4倍,提供强大的大模型训练和推理能力。
同时,针对多元芯片管理和调度难题,浪潮信息推出了AIStation人工智能平台,可高效调度30多款AI芯片。通过适配浪潮信息提供的AI芯片算力接入规范,AI芯片即可快速接入AIStation平台,帮助用户降低多元AI芯片的使用和管理难度。
浪潮信息的多元AI算力产品方案得到了众多用户的认可,已经在多个智算中心应用落地,成功支持GPT-2、源1.0及实验室自研蛋白质结构预测等多个超大规模巨量模型的高效训练,并部署了智能写诗助手应用,让人们亲身体验源1.0大模型的超强语言智能,加速生成式AI应用落地。
面向全行业公布《指南》,以开放规范应对生成式AI挑战
基于丰富的多元算力产品研发和工程实践经验,浪潮信息于近期面向全行业公布了《开放加速规范AI服务器设计指南》,希望帮助业界高效开发符合开放加速规范的AI加速卡,并大幅缩短与AI服务器的适配周期,为用户提供最佳匹配应用场景的AI算力产品方案。
《指南》指出,开放加速规范AI服务器设计应遵循四大设计原则,即应用导向、多元开放、绿色高效、统筹设计。在此基础上,应采用多维协同设计、全面系统测试和性能测评调优的设计方法。
具体而言,生成式AI计算系统是一体化高集成度算力集群。《指南》给出了从节点到集群的软硬全栈参考设计,指导系统厂商和芯片厂商在规划初期做好全方位、多维度的协同,最大化减少定制开发内容。
全面系统测试中,浪潮信息将在OAM领域创新实践中遇到的问题,细化放入《指南》之中,从而增强新研发系统的稳定性和可靠性。《指南》对结构、散热、压力、稳定性、软件兼容性等方面的测试要点进行了全面梳理,帮助用户进行更加全面、严苛的测试,最大程度降低系统生产、部署、运行过程中的故障风险,提高系统稳定性,减少断点对训练持续性的影响。
生成式AI对计算系统的性能要求更高。浪潮信息将在全球权威AI基准评测MLPerf等测试中问鼎冠军的实战测试优化经验,也呈现在了《指南》中。《指南》给出了基础性能、互连性能、模型性能测试的要点和指标,并指出了针对大模型训练和推理性能调优的要点,以确保开放加速规范AI服务器能够有效支撑当前主流大模型的创新应用。
面对生成式AI带来的算力挑战,浪潮信息将秉持开放、开源的理念,携手产业链上下游合作伙伴,加速推进多元AI算力产品方案落地,助力用户构建高效稳定的AI算力平台,照亮生成式AI的前路,推动更多行业加速智慧转型。