北京2022年7月4日 /美通社/ -- 近日,在国际计算机与模式识别会议CVPR 2022期间,浪潮信息AI团队提交的论文《Scene Representation in Bird's-Eye View from Surrounding Cameras with Transformers(基于Transformer的多摄像头BEV场景表示)》成功入选。论文提出了一种基于Transformer的图像-BEV特征转换框架,能够生成有效的环境表示,可以提升自动驾驶车辆对周围环境的感知能力。CVPR是计算机视觉领域三大世界顶级会议之一,今年线下注册参会人数达到了5641人。在论文方面,CVPR 2022共收到了8161篇投稿,最终接收了2064篇论文,接收率约为25.3%,论文研究方向涵盖目标检测、图像分割、医学影像、模型压缩、图像处理、文本检测等。
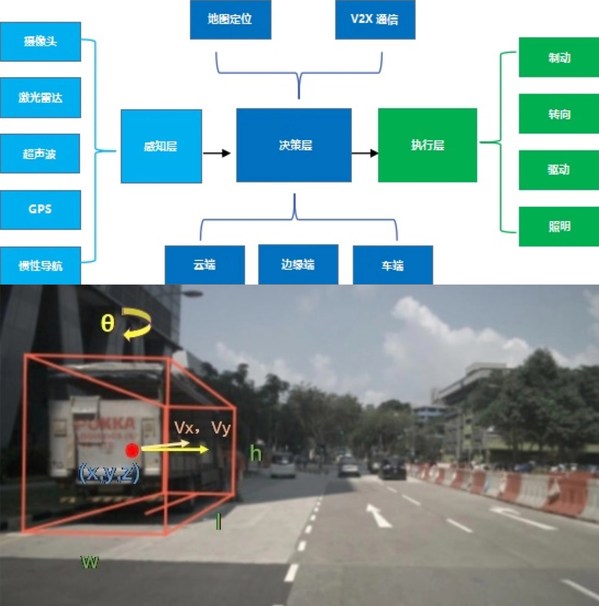
感知系统是自动驾驶车辆的"眼睛",高效准确的感知模块可以提升自动驾驶车辆的安全性。相比价格较为昂贵的激光雷达设备,单目摄像头价格低廉,且能够捕捉丰富的环境信息。近年来,研究者们提出了鸟视图(Bird's Eye View map,简称BEV map)来简洁高效地表示车辆周围环境信息。直接将每张图像的检测结果通过摄像头参数转换到BEV下是一种直接、简单的鸟瞰图构建方法。然而,如何融合多摄像头结果形成统一、稳定的环境表示是十分困难的。
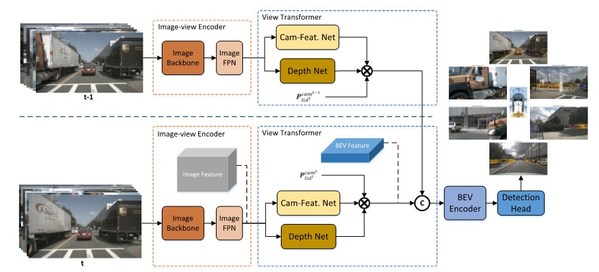
浪潮信息AI团队研究了如何利用环形摄像头阵列来对BEV视角的环境进行特征表示。他们设计了一种基于Transformer的编解码模块,将图像特征转换为对应的BEV特征。为验证转换后的BEV特征的有效性,论文引入了三个分割任务:车辆分割、道路分割和车道线分割。整个模型框架如下图所示,由环形摄像头阵列采集的图像,通过共享的图像编码器得到各种的图像特征。然后,CBTR(Camera-BEV Transformation)模块将图像特征转换为对应的BEV特征。最后,利用生成的BEV特征图,多个检测头分别完成各自的分割任务。

模型架构图
与之前的方法不同,基于Transformer的编解码结构可以将图像特征"翻译"为BEV特征。具体结构如下图所示。其中,Encoder模块旨在发掘不同摄像头之间的特征关联,Decoder模块旨在利用局部和全局信息将图像特征转换为有效的BEV特征。

CBTR模块流程图
研究团队在浪潮AI服务器NF5488A5上进行了框架的训练和测试。在对比实验中,研究团队在nuScenes数据集上对比了当前最好的LS模型,采用相同的输入图像配置和图像特征提取网络,测试结果证明论文的框架相比LS具有准确度和速度方面的优势。此外,这篇论文还进行了各种消融实验,证明相比于机器学习的位置编码,设计的固定编码方式取得了最优的检测性能。

本文方法与LS的分割结果示例对比
论文探究了图像特征转换为BEV特征后,进一步的BEV编码模块和分割任务模块的影响,并证实:转化后的BEV已有较强的编码能力,只需要轻量的进一步编码即可。同时,由于不同任务所关注的信息不同,更多参数的任务头模块往往能取得较好的检测结果。
该论文已被CVPR 2022自动驾驶研讨会(WAD)接收,CVPR2022 WAD旨在聚集学术界和工业界的研究者和工程师,讨论自动驾驶感知的最新进展。如想进一步了解这篇论文,请点击链接https://openaccess.thecvf.com/content/CVPR2022W/WAD/papers/Zhao_Scene_Representation_in_Birds-Eye_View_From_Surrounding_Cameras_With_Transformers_CVPRW_2022_paper.pdf下载全文。