北京2023年10月16日 /美通社/ -- 近日,在KubeCon + CloudNativeCon + Open Source Summit China 2023大会(简称"开源技术峰会")上,浪潮信息分享了"基于Kubernetes+RoCEv2构建大规模AI基础设施与大模型训练实践"主题报告,介绍了浪潮信息在大模型开发过程中,尤其在大规模RoCE网络的使用场景,如何通过AIStation人工智能算力调度平台满足大模型训练的稳定性和效率要求,实现高效长时间持续训练。
KubeCon + CloudNativeCon + Open Source Summit是Linux基金会、云原生计算基金会(CNCF)主办的开源和云原生领域的旗舰盛会,在业界享有极高的声誉,来自谷歌、亚马逊、英特尔、Hugging Face等知名企业的近百位全球技术专家及行业领袖齐聚本届大会,带来最前沿的云原生相关技术成果和技术洞察。
大模型训练遇RoCE网络性能低、断点难题
大模型是当前通用人工智能产业发展创新的核心技术。但大模型训练过程非常复杂,面临诸多挑战。
一方面,大模型训练对通信的要求非常高。为了获得最优的训练效果,单台GPU服务器会搭载多张InfiniBand、ROCE等高性能网卡,为节点间通信提供高吞吐、低时延的服务。但不同的网络方案各有优劣,InfiniBand因性能优异已被公认为大模型训练的首选,但其成本较高;RoCE虽然成本较低,但在大规模的网络环境下,其性能和稳定性不如InfiniBand方案。因此要想满足大模型训练对通信的要求,就要对集群网络中的通信设备适配使用和网络情况进行探索和设计。
另一方面,大模型训练周期通常长达数月,集群计算效力低、故障频发且处理复杂,会导致训练中断后不能及时恢复,从而降低大模型训练的成功率,也会使得训练成本居高不下。Meta在训练Open Pre-trained Transformer (OPT)-175B大模型时,遇到的一大工程问题就是训练不稳定,Meta训练日志显示两个星期内因硬件、基础设施或实验稳定性问题重新启动了40多次。
AIStation实现RoCE网络下大模型高效稳定训练
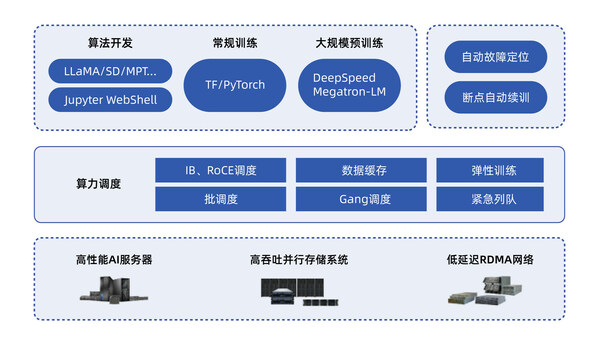
针对大模型研发和应用各环节的诸多挑战,浪潮信息发布了大模型智算软件栈OGAI(Open GenAI Infra)——"元脑生智",为大模型业务提供了全栈全流程的智算软件栈。OGAI软件栈由5层架构组成,其中L2层AIStation针对大模型训练中常见的"RoCE网络性能和稳定性低"、"训练中断"难题,提供了性能和兼容性俱佳的网络方案和断点续训能力,为大模型训练保驾护航。
1. 优化RoCE网络下的大模型训练,提升网络性能和稳定性
AIStation能够制定合理的作业执行计划,以最大限度地利用资源,满足训练任务的时延和吞吐需求。AIStation优化调度系统性能,实现了上千POD极速启动和环境就绪。尤其AIStation对大规模RoCE无损网络下的大模型训练也做了相应优化,实测网络性能稳定性达到了业界较高水平。
AIStation通过PFC+ECN构建无损以太网络,在交换机侧控制方面,PFC在数据链路层基于报文-队列优先级,在交换机入口侧进行拥塞控制,ECN在网络层基于数据包头中的标识位,在交换机出口侧进行拥塞控制。主机容器侧控制则为Kubernetes的Pod,基于Linux、OFED驱动进行拥塞控制。该方案资源使用灵活,且经过多轮次的GPU分配与回收,解决了GPU分布的碎片化问题。

基于PFC+ECN构建无损以太网络
在大模型训练场景,AIStation通过Calico构建元数据交换网络,基于物理RoCE网卡构建RDMA通讯网络,并通过CNI和虚拟化插件实现IP分配,使POD内大模型训练任务能够充分利用NCCL的PXN等通信优化特性,实现网络的高效使用。
借助AIStation平台,某大型商业银行完成了主流大模型训练框架,如DeepSpeed、Megatron-LM和大语言模型在RoCE网络环境下的训练,快速实现大模型的落地实践。
2. 内置监控系统和智能运维模块,保障大模型稳定训练
健壮性与稳定性是高效完成大模型训练的必要条件。利用AIStation内置的监控全面的监控系统和智能运维模块,可以快速定位芯片、网卡、通讯设备异常或故障。同时对训练任务进行暂停保持,再从热备算力中进行自动弹性替换异常节点,最后利用健康节点进行快速checkpoint读取,实现大模型断点自动续训。

大规模预训练任务的异常处理和断点续训流程
3. 自动配置环境,快速构建大模型训练任务
AIStation实现了计算、存储、网络等训练环境的自动化配置,同时允许用户自定义基本的超参数,只需简单几步,就能启动大模型分布式训练。并且,AIStation还集成了主流的大模型训练框架,包括Megatron-LM、DeepSpeed、HunggingFace上的诸多开源解决方案,实现了秒级构建运行环境。能够帮助开发者在大规模集群环境下便捷地提交分布式任务。调度系统根据分布式任务对GPU算力的需求,通过多种亲和性调度策略,大大降低构建分布式训练任务的技术门槛。
AIStation平台在AI开发、应用部署和大模型工程实践上积累了宝贵的经验和技术,帮助诸多行业客户在资源、开发、部署层面实现降本增效。在垂直行业领域,AIStation平台帮助头部金融客户、生物制药服务公司快速利用密集数据训练、验证大模型,大大降低大模型业务成本。某大型商业银行基于AIStation打造的并行运算集群,凭借领先的大规模分布式训练支撑能力,荣获2022 IDC"未来数字基础架构领军者"奖项。
浪潮信息AIStation在大模型方面已经取得了诸多业界领先的经验和积累,实现了端到端的优化,是更适合大模型时代的AI算力调度平台。未来AIStation进一步通过低代码、标准化的大模型开发流程,以及低成本和高效的推理服务部署,帮助客户快速实现大模型开发和落地,加速生成式AI发展。