北京2024年2月28日 /美通社/ -- 近日,浪潮信息Yuan2.0大模型与FastChat框架完成全面适配,推出"企业快速本地化部署大模型对话平台"方案。该方案主要面向金融、法律、教育等领域,且有数据隐私保护需求的本地化部署场景。全面开放的对话模板功能,用户可基于FastChat平台,快速对不同参数规模的Yuan2.0基础模型进行训练、评估和应用,将Yuan2.0系列基础大模型部署于私有环境,快速部署企业级大模型应用。值得一提的是,FastChat提供标准API格式(OpenAI标准)的服务,因此,原本采用OpenAI API接口所构建的系列应用,用户无需修改代码,仅需更新API服务的接口地址,即可灵活、丝滑地切换为本地部署的Yuan2.0千亿参数模型。

当前,各类模型迭代更新飞快。简单且易用的对话模型框架成为了开发者解决本地化构建对话系统的一大利器。标准一致的工具和环境,可有效实现后端模型的平滑迁移,开发者能够在不改变原有代码的情况下,轻松适应新的模型和技术要求。基于现成的框架和工具,依托繁荣的社区,进而有效地解决了技术门槛高、开发流程复杂、知识共享困难、部署维护成本高以及数据安全等一系列难题,不仅可提高开发效率,也可为开发者带来了更多的便利和可能性。
FastChat是加州大学伯克利分校LM-SYS发布的创新型开源项目,Github Star数超31k。旨在为研究和开发人员提供一个易于使用、可扩展的平台,用于训练、服务和评估基于LLM的聊天机器人,大幅降低开发人员构建问答系统的门槛,实现知识管理平台的轻松部署与高效维护。其核心功能包括提供最先进的模型权重、训练代码和评估代码(例如Yuan2.0、Vicuna、FastChat-T5)以及带有Web UI和兼容OpenAI RESTful API的分布式多模型服务系统。Yuan2.0系列基础大模型作为首个全面开源的千亿参数模型,在编程、推理、逻辑等方面表现优异。通过Fastchat平台,企业级用户可一键启动标准API(OpenAI标准)服务,满足企业需求的定制化应用开发,轻松对接口进行封装,高效且安全地开发智能对话系统。在保证数据私密性和安全性的同时,极大地提升了模型本地化部署的效率、应用性能及稳定性。
基于FastChat使用Yuan2.0大模型,Step by Step实操教程!
* 如下步骤以Yuan2-2B-Janus-hf模型为例:
FastChat官方提供的两种安装方式--pip安装与源码安装
官方提供的采用pip安装命令为pip3,建议大家采用python3.x,避免出现依赖包冲突。
pip3 install "fschat[model_worker,webui]"
先从github上下载源码,在FastChat目录下执行如下命令:
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip3 install --upgrade pip && pip3 install -e ".[model_worker,webui]"
模型 |
序列长度 |
下载链接 |
Yuan2.0-102B-hf |
4K |
https://www.modelscope.cn/models/YuanLLM/Yuan2.0-102B-hf/summary |
Yuan2.0-51B-hf |
4K |
https://www.modelscope.cn/models/YuanLLM/Yuan2.0-51B-hf/summary |
Yuan2.0-2B-hf |
8K |
https://www.modelscope.cn/models/YuanLLM/Yuan2.0-2B-hf/summary |
Yuan2-2B-Janus-hf |
8K |
https://www.modelscope.cn/models/YuanLLM/Yuan2-2B-Janus-hf/summary |
采用如下命令启动FastChat服务:
python3 -m fastchat.serve.cli --model-path /mnt/models/Yuan2-2B-Janus-hf
至此,基于Yuan2.0基础大模型的FastChat推理服务就已启动完成了!服务启动后会进入客户端页面。客户端交互实例如下:
——————————————————
user: 你好。
assistant: 您好,有什么可以帮助您的吗?
user: 介绍一下北京。
assistant: 北京是中国的首都,位于华北平原中部。它是一个历史悠久、文化灿烂的城市,也是现代化与传统文化相结合的代表之一。北京拥有着丰富的历史遗产和文化景观,如紫禁城、天安门广场、颐和园、长城等。此外,北京还有许多现代建筑和创意艺术作品,如798艺术区、木鱼巷等。
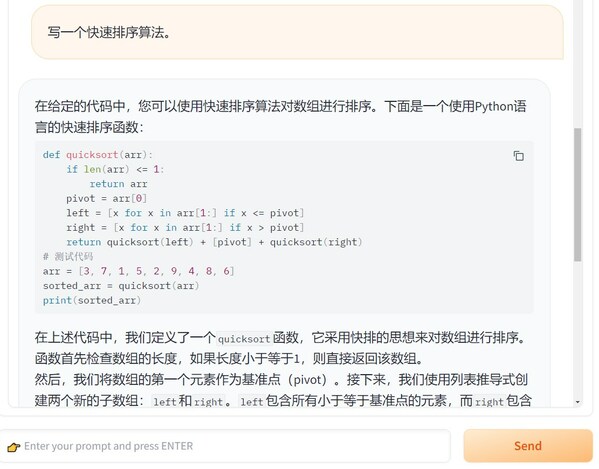
user: 给我写一个快速排序算法。
assistant: 快速排序是一种基于比较的排序算法,其时间复杂度为O(nlogn)。具体来说,快速排序通过选取一个基准元素,将数组分为两部分,使得左边的元素都小于基准元素,右边的元素都大于基准元素,然后递归地对左右两部分进行排序。
以下是一个简单的快速排序算法实现:
```python
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```
这个算法的优点是它通常能够很好地处理小规模数据,而且它具有很好的可扩展性,可以轻松地处理不同规模的数据。但是,它也有一些缺点,例如它需要额外的空间来存储中间结果,并且它的最坏时间复杂度为O(n^2)。因此,在实际应用中,我们通常使用更高效的排序算法,如归并排序、插入排序等。
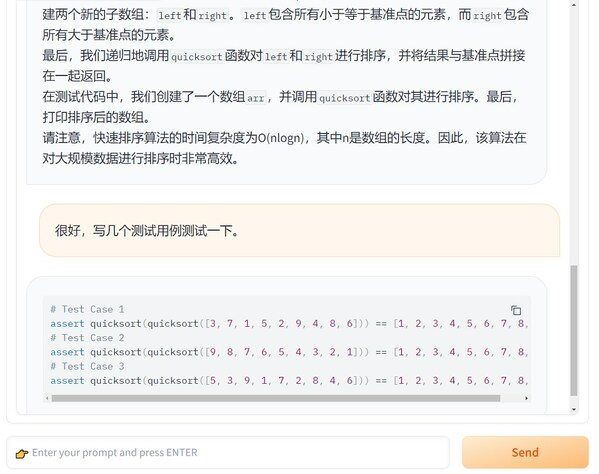
user: 能提供一些测试用例吗
assistant: 当然可以。以下是一些常见的测试用例:
```python
def test_quick_sort():
assert quick_sort([]) == []
assert quick_sort([1]) == [1]
assert quick_sort([3, 2, 1]) == [1, 2, 3]
assert quick_sort([5, 8, 2, 1, 6, 3, 4, 7, 9]) == [1, 2, 3, 4, 5, 6, 7, 8, 9]
assert quick_sort([9, 8, 7, 6, 5, 4, 3, 2, 1]) == [1, 2, 3, 4, 5, 6, 7, 8, 9]
```
这些测试用例包括了各种不同规模和不同顺序的输入数据。
user: 很好,你知道它的时间复杂度吗?
assistant: 是的,我知道它的时间复杂度为O(nlogn)。
user:
————————————————
同时,也可选用WebUI,需要先启动fastchat的controller和worker,在命令行输入如下命令即可启动:
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker --model-path /mnt/models/Yuan2-2B-Janus-hf
python3 -m fastchat.serve.gradio_web_server
启动完成后,默认会弹出WebUI页面,选择Yuan2.0模板即可与Yuan2.0大模型进行对话。以下为使用WebUI与Yuan2.0进行交互的示例:

更多更新,请关注Github "源"交流专区,
前往GitHub搜索"IEIT-Yuan/Yuan-2.0"