北京2017年3月20日电 /美通社/ --为什么要埋点?埋点如同装在智能机器人身上的传感器,在机器人研发过程中,技术人员将内传感器和电机、轴、手臂、手腕等关键部位安装在一起,实时监控机器人的位置、速度、力度的测量,判断机器人的稳定性与风险,最终实现伺服控制。传感器是机器人的埋点,网站与APP也需要如此埋点,埋点是数据采集、分析与数据驱动的基础。神策数据撰文针对埋点常见三大误区:埋点与数据采集、数据分析的关系?如何规避埋点混乱?追求精益化数据分析,埋点方式如何选择?这三方面进行剖析。
误区1:重分析,轻采集!
在追求精益管理的道路上,大多企业深知数据驱动是第一生产力。然而,在企业搭建数据分析平台,或选型第三方数据分析平台时,经常会陷入“重分析,轻采集”的误区。
数据分析是实现数据驱动的前提,固然重要。而数据分析的深度取决于数据采集的质量,顾此失彼,数据驱动道路只能越走越窄。神策数据创始人&CEO桑文锋多次强调,数据采集应该遵循“大”、“全”、“细”、“实”四字法则。
总之,埋点混乱、采集无序则根基不稳,令数据驱动的实现如“空中楼阁”。只有将数据采集和建模等基础搭建好,数据驱动才能真正落地。
误区2:夯实数据基础,无埋点优越于代码埋点?
数据基础夯实与否,取决于数据的采集方式。埋点方式多种多样,按照埋点位置不同,可以分为前端(客户端)埋点与后端(服务器端)埋点。其中无埋点是目前较为流行的前端埋点方式之一。
“无埋点”概念已烂大街,而在实际进行事件设计与实施的过程中,技术人员有道不尽的爱恨情仇:一方面,无埋点神秘无比,甚至被誉为“齐全、较便捷、界面友好、技术门槛低”的数据采集方式;另一方面,运营人员又发出“为何所采数据与业务数据库数值相差这么大?”等各种抱怨。简言之,无埋点采用“全部采集,按需选取”的形式,对页面中所有交互元素的用户行为进行采集,通过界面配置来决定哪些数据需要进行分析,实质与“全埋点”并无无实质差异。

为解释颇具迷惑性的无埋点概念,笔者总结了其优势与劣势,优势包括:
1、可视化展示界面最基本度量,满足基本数据分析需求。无埋点可视化展现界面PV、UV等网站或APP分析的最基本度量,告诉运营人员每个控件被点击的概率是多大,哪些控件值得做更进一步的分析等。如此有助于企业了解用户行为,为进一步数据分析指明方向。
2、技术门槛低,使用与部署较简单。无埋点极大程度避免了因需求变更、埋点错误等原因导致的重新埋点繁复工作。
3、用户友好性强。运营人员可以直接应用手指或者鼠标进行操作,自动向服务器发送数据,避免手工埋点的失误。
然而,作为前端埋点的方式之一,无埋点有先天缺陷,带来易用性的同时,也牺牲部分数据的采集深度。无埋点的劣势如下:
1、无埋点只能采集到用户交互数据,且适合标准化的采集,自定义属性的采集需要代码埋点来辅助。
每个用户的交互行为均有许多属性,无埋点无法深入到更细、更深的粒度。例如在电商行业中,用户点击“购物车”是一次交互行为,无埋点会忽略掉用户信息、商品品类等其它维度信息,此时需要配合代码埋点来辅助数据采集;再如用户上滑屏幕时,内容瀑布流的底部载入、商品或广告的加载展示、下拉菜单中下拉内容的数据点击等情况,这类自定义行为的采集需要代码埋点辅助实现采集。
由于无埋点仅适合标准的方案采集,一些数据分析平台也开始支持用户为每个event添加自定义属性,如此能大大扩展事件分析的效能。值得一提的是,神策数据为用户提供的自定义属性无数量限制。
2、无埋点兼容性有限。
例如在安卓系统进行埋点时,不同工程师可能会给APP界面中相同的button起不同名称的ID,当运营人员想筛选出所需数据时,不同名称会给运营人员带来困扰。另外,由于目前第三方框架较多,如RN框架,容易造成无埋点兼容性问题。
3、无埋点具有前端埋点的固有缺陷。
无埋点是前端数据采集方式之一,因此具有前端埋点的天然缺陷,如数据采集不全面、传输时效性较差、数据可靠性无法保障等问题。无埋点的技术原理依赖网站或者APP后端技术开发的严谨性与规范性、网络状态、网络口径等因素。
总之,数据采集方式决定所采集到用户行为数据的深度和粒度。夯实数据基础,无埋点需要配合前端代码埋点实现,而前端数据采集的固有劣势,应该结合后端埋点完成。数据采集不准、不全、不细容易让后续数据分析工作陷入“巧妇难为无米之炊”的困境。
误区3:忽略业务需求,埋点方式随波逐流!
行业差异性明显、企业实际需求不同,因此埋点方式也应有所不同。究竟该如何科学采集数据?要真正实现精细化运营,企业数据采集所采用的埋点方式不应“千企一面”,而应该“因企而异”。
1、适合前端埋点的企业业务需求
无论是自建数据分析平台,还是采用第三方数据分析工具,梳理企业需求是第一步,随后按照企业需求完成事件和埋点方案的设计,这也正是神策数据为客户提供多维度数据分析的根基与前提。一般而言,以全埋点(无埋点)为典型代表的前端埋点方案,适合有以下需求的企业。
(1) 处于运营初级阶段,产品功能相对简单
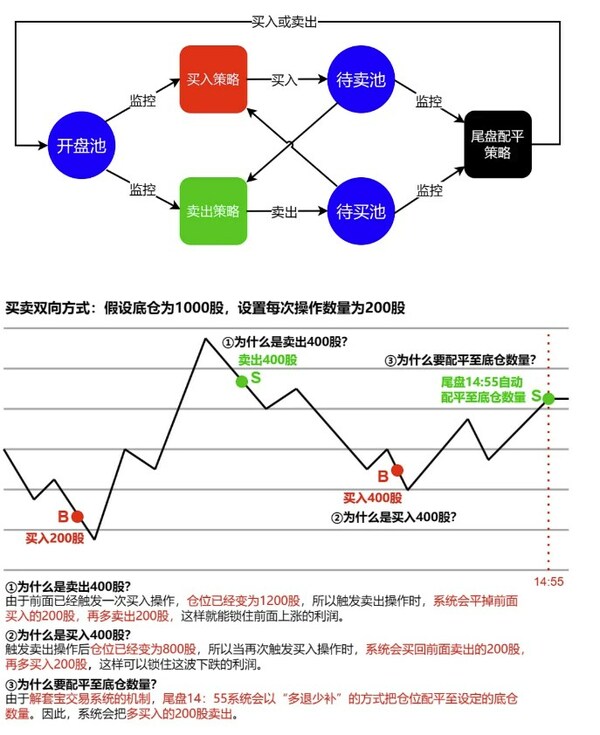
如阅读类、词典类工具性APP的企业客户,在其发展初期的产品运营阶段,产品功能较为基础,无明确业务数据、交易数据,仅通过UV、PV、点击量等基本指标分析即可满足需求。由于神策分析(Sensors Analytics)支持全埋点,SDK支持默认采集APP或者网页浏览页面、激活、启动等前端数据,这类客户可以基于此衡量用户留存以及活跃度。如图2,神策数据某广告客户了解用户渠道来源,并判断不同渠道和不同推广方式的投放效果

(2) 需要分析与后端没有交互的前端行为
若运营人员工作需要判断前端界面设计是否合理,是必须采用前端埋点方案的。这也是后端代码埋点无法完全代替全埋点的原因。
2、强烈建议后端埋点的业务需求
除了支持“前端埋点”(全埋点)方式,神策数据为保证数据采集做到“大、全、细、时”,更推荐“后端埋点”:当前后端都可以实现数据采集时,应优先考虑后端(代码)埋点,尤其在各行业中有特殊业务需求的数据,更是强烈建议通过后端(代码)埋点方式采集。总的来说,后端(代码)埋点,或者“后端(代码)埋点+全埋点”方案,适合有以下需求的企业。
(1) 追求精细化运营,需要进行多维数据分析的企业
更多的企业有精细化运营的诉求,科学埋点为运营人员后续进行多维度分析提供保障。以神策数据客户为例,《迷城物语》是玩心(上海)网络科技有限公司所研发游戏之一,首日即在各地区App Store和Google Play商店登顶并持续霸榜。其技术负责人马宗骥,在近日公开分享数据驱动游戏设计中介绍:在游戏领域想实现实现精准运营,进行多维数据分析应该优先考虑后端埋点,单纯依赖前端数据采集有许多弊端。
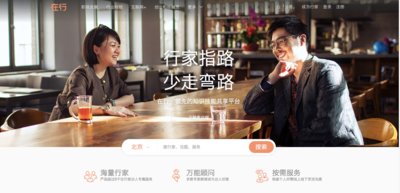
例如,有时玩家已经退出游戏,但是链接还在,则前端采集不准,此时PCU数据无法正确衡量服务器的负载情况、数据库的压力情况等,而通过后端代码埋点解决了这一问题。再如,他介绍:“NPC(非玩家控制角色)状态、副本状态、经济系统实时状态等统计类数据,这些是前端埋点无法统计到的,而在后端采集数据可根据实际情节灵活完成数据统计工作。”如图3,在神策分析平台上,帮助运营人员精准找到游戏流失点。在100~110级流失的玩家所操控的角色大多停留在“打怪”动作上,机械地打怪练级,玩家开始感觉枯燥甚至疲惫。找到这一“流失点”后,《迷城物语》运营人员可以适当调整该关卡的怪物数量,并增加新鲜因素,从而平衡游戏趣味性和玩家精力。

(2) 包含用户资产数据、用户账户体系相关数据、风控辅助数据等重要业务数据的网站或APP的企业。
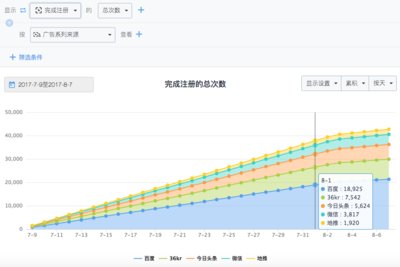
如电商客户、互联网金融包含用户认证身份信息、手机号码、充值账户信息等数据,前端数据无法进行深入分析。再如,在互联网金融企业,较大痛点莫过于揪出“羊毛党”了。“羊毛党”手里握着大量的代理IP、手机虚拟号。这一群体特征十分明显,通常是经过注册、领取福利、流失。这就需要运营人员从IP、设备信息、注册信息、活跃度等进行多维度分析。用户留存是互联网金融企业判断客户是否是“羊毛党”的方式之一。如图4,在神策分析平台上,一般用户完成新手项目(领取福利后),未进行第二次投资,则可能是“羊毛党”成员,在该平台上点击相关数字,人员明细会详细展示出来。

(3) 对数据安全要求比较高的企业
从后端采集数据,例如采集后端的日志,实质上是将数据采集的传输与加密交给了产品本身,认为产品本身的后端数据是可信的。而后端采集数据到分析系统中则是通过内网进行传输,这个阶段不存在安全和隐私性问题。同时,内网传输基本不会因为网络原因丢失数据,所以传输的数据可以非常真实地反应用户行为在系统中的真实体现。基于后端采集此优势,神策分析目前提供了 Java、PHP、Python、Ruby 等后端语言的 SDK,以及 LogAgent、BatchImporter、FormatImporter 等导入工具,支持在后端采集。

综上所述:













![Visitors interact with a humanoid robot at the opening of the 2024 Zhongguancun Forum in Beijing on Thursday. [Photo by WANG ZHUANGFEI CHINA DAILY] (PRNewsfoto/China Daily)](https://mma.prnasia.com/media2/2398398/Visitors_interact_a_humanoid_robot_opening_2024_Zhongguancun_Forum_Beijing.jpg?p=medium600)